

インテルXeon 6、エヌビディアのDGX Rubinアーキテクチャに採用。7%急騰後に株価が下落した理由とは?



AIポッドキャスト
インテルは、NVIDIAの次世代AIサーバー「DGX Rubin NVL8」にXeon 6プロセッサが採用されることを発表した。これにより、AIワークロードが大規模学習からリアルタイム推論へと移行する中で、CPUがAIシステムアーキテクチャの中核コンポーネントとして戦略的に回帰した。Xeon 6はタスクのオーケストレーションやGPUへのデータ転送などを担い、計算能力とアプリケーションを繋ぐ。この提携は、AIエコシステムにおけるx86アーキテクチャの重要性を再確認し、CPU、GPU、DPUが連携するヘテロジニアス構成への進化を示唆する。Xeon 6は、大容量メモリサポート、高速メモリ帯域幅、PCIe 5.0、プライオリティ・コア・ターボ、Intel TDX、NVIDIA Dynamoサポートといった技術的優位性を持つ。

TradingKey — 2026年のNVIDIA GTCカンファレンスにおいて、インテル( INTC)は、同社のXeon 6プロセッサがNVIDIA( NVDA)の次世代フラグシップAIサーバー、DGX Rubin NVL8の主要CPUとして、正式に採用されることを発表した。
この提携は、Blackwellプラットフォームで確立されたx86アーキテクチャのシナジーを拡大させるだけでなく、AIワークロードが大規模学習から「至る所でのリアルタイム推論」へと移行する重要な局面において、AIシステムアーキテクチャの中核コンポーネントとしてCPUが戦略的に回帰したことを強調している。
エージェンティックAIと推論システム専用に設計されたフラグシップサーバーであるNVIDIAのDGX Rubin NVL8において、Xeon 6プロセッサはタスクのオーケストレーション、メモリ管理、スケジューリング、GPUアクセラレータへのデータ転送などの核心的な役割を担い、計算能力とアプリケーションを繋ぐ重要な架け橋として機能する。
提携のニュースを受けて、月曜日のインテルの株価は一時7.4%急騰し、日中高値の49.17ドルを付けたが、その後は失速して0.02%安の45.76ドルで引け、同日のフィラデルフィア半導体株指数の構成銘柄の中で最もパフォーマンスの悪い銘柄の一つとなった。
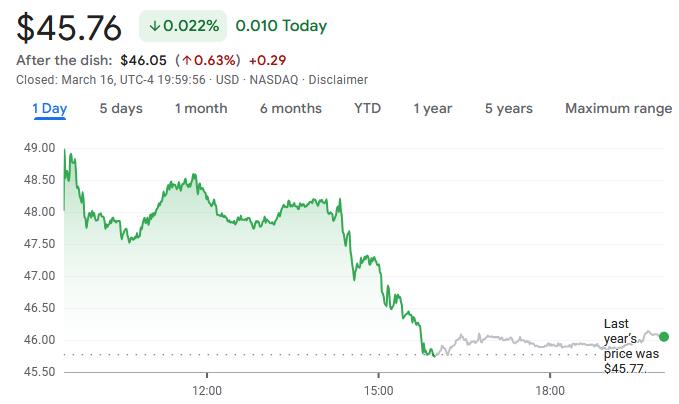
この「行って来い」の株価の動きは、伝統的なCPUメーカーのAIシフトに対する市場の複雑な心理を反映している。投資家は、インテルとNVIDIAの提携がAIサーバー分野での足場を築くための重要な一歩であるという戦略的意義を認める一方で、GPUが支配する市場における同社のAI事業の収益性については慎重な姿勢を崩しておらず、信頼回復にはより明確な業績見通しが必要とされている。
しかし、調査会社のリンクス・エクイティ・ストラテジーは強気な見方を維持しており、アナリストレポートの中で、NVIDIA DGX Rubin NVL8システムへのインテルXeon 6の統合は、両社の提携が技術的概念から商業製品へと移行したことを示すものだと指摘した。今後、この提携の商業的価値は、製品の投入時期や潜在的な収益貢献を通じて測ることができるだろう。
戦略的要衝に回帰するCPU
業界全体の構図から見れば、今回のインテルとNVIDIAの提携の意義は、単なる部品供給の関係をはるかに超えるものである。
インテルにとって、これは「AI時代にCPUは不要である」という業界の偏見を打ち破る的確な「戦略的防御」の動きであり、推論の時代においてCPUのスケジューリング、メモリ管理、セキュリティ機能がAIシステムの効率的な運用のために不可欠な支柱であることを証明している。
AI業界全体にとっては、AIエコシステムにおけるx86アーキテクチャの強力な「堀」を再確認するものとなる。膨大な導入実績と成熟したソフトウェアエコシステムは、企業のAI移行における技術的障壁と総保有コスト(TCO)を効果的に低減できる。さらに重要なのは、AIインフラが「アーキテクチャの再構築」に向かっており、将来のAIシステムはGPUの独壇場ではなく、CPU、GPU、DPUが連携するマルチチップのヘテロジニアス(異種混在)構成へと進化することを示唆している点だ。
注目すべきは、インテルのXeon 6が大規模なNVL72ラックではなく、NVIDIAのDGX Rubin NVL8ラックシステムに統合されている点である。これは、Xeonプロセッサを基本的な8基のGPUノードのホストプロセッサとして位置づけ、データの事前処理、モデルの読み込み、KVキャッシュ管理、タスクの調整を担わせるという、Blackwellプラットフォームで見られた提携の論理を踏襲している。
業界関係者の間では、これが提携の出発点に過ぎないとの見方が大勢を占めている。AI推論の需要が拡大し続けるにつれ、XeonプロセッサはNVL72のようなハイパースケールのラックシステムにもさらに統合されていくことが予想される。
インテルXeon 6の技術的優位性
インテルは、XeonシリーズがDGX Rubin NVL8システムのコアCPUに採用された理由として、高速なハードウェアメモリのサポート、多様なワークロードにわたるバランスの取れたパフォーマンスから、長期的なコスト管理能力、市場で実証済みの成熟した企業向けソフトウェアエコシステムに至るまで、多角的なシステムレベルの優位性を挙げている。
推論シナリオにおける大規模モデルのKV(キー・バリュー)キャッシュ需要の高まりに対応するため、Xeon 6プラットフォームは最大8TBのシステムメモリをサポートしており、これは大規模言語モデルの実行や重要なキー・バリューデータの保存に不可欠な容量である。
同時に、MRDIMMテクノロジーを採用することで、Xeon 6は前世代比2.3倍のメモリ帯域幅を実現し、最大8800 MT/sに達した。この飛躍的な進歩により、GPUアクセラレータへのデータ転送が大幅に高速化され、推論シナリオで一般的だったGPUへのデータ供給のボトルネックを根本から解消している。
システムの接続性に関しては、Xeon 6は高帯域幅のアクセラレータ接続を可能にするPCIe 5.0レーンを提供し、マルチGPUクラスター間での効率的なデータフローを確保している。
インテルの革新的な機能「プライオリティ・コア・ターボ(Priority Core Turbo)」は、推論シナリオにおける複雑なスケジューリング要件向けに特別に設計されている。強力なシングルスレッド性能をオーケストレーション、スケジューリング、データ転送タスクに集中させることで、複雑なマルチタスクの負荷下でもGPUが高い効率を維持できるようにしている。
セキュリティ面において、Xeon 6プロセッサはIntel Trust Domain Extensions(TDX)技術を利用し、CPUからGPUに至るデータパス全体をエンドツーエンドで保護する。暗号化されたバウンスバッファがハードウェアベースの分離と認証を追加し、データセンター、クラウド、エッジへの展開におけるAI推論の機密コンピューティング要件に完全に適合している。
さらに、Xeon 6はNVIDIAの推論オーケストレーションフレームワーク「Dynamo」へのサポートを追加している。このフレームワークにより、同一クラスター内のCPUとGPUのリソースが柔軟なヘテロジニアス・スケジューリングを実現し、システム全体の効率をさらに向上させることが可能となる。
このコンテンツはAIを使用して翻訳され、明確さを確認しました。情報提供のみを目的としています。











コメント (0)
$ボタンをクリックし、シンボルを入力して、株式、ETF、またはその他のティッカーシンボルをリンクします。