

Google TPUが主導する「Googleチェーン」が市場の動向をリード

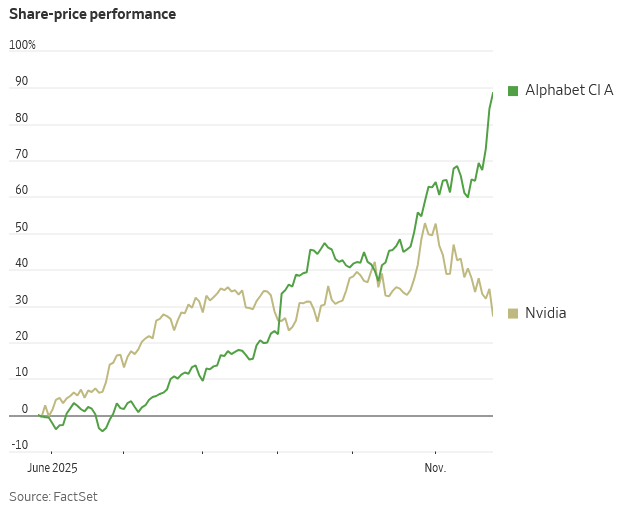
TradingKey - 最近、市場を席巻している人工知能(AI)取引に関する懸念は、NVIDIA(エヌビディア)に大きな打撃を与えています。AI投資家の象徴だった同社は、今や市場調整の最大の被害者となっています。一方、Googleはこれに逆行しています。TPUにおける重要な進展を武器に、Googleの親会社であるAlphabetの株価は上昇を続け、投資家からはNVIDIAのGPUに代わる数少ない代替案の一つと見なされています。今月までのAlphabetの株価上昇率は15%に達しているのに対し、NVIDIAの株価は12%下落しました。
Google Gemini 3が依拠する自社開発チップ事業は、新たな評価再構築の触媒となっています。投資家は、AlphabetがAppleを追い抜き、世界第2位の企業になる可能性さえ見込み始めています。
NVIDIAを使わず、Gemini 3はいかに訓練されたのか?
Gemini 3の訓練は、完全にGoogleの最新世代TPUスーパーコンピューティングクラスターに基づいています。このモデルは、Googleの第7世代TPUである「Ironwood(アイアンウッド)」アーキテクチャを使用しており、全体の計算能力は前世代から約10倍に向上しています。単一のクラスターで数万個のチップを接続でき、各TPUは三次元メッシュで接続されているため、大量のデータを効率的に分散・集約し、計算能力のボトルネックを根本的に緩和します。
さらに注目すべきは、Ironwoodが最先端の光インターコネクト技術(OCS 光スイッチ)を導入したことです。これにより、チップ間は光信号を介して直接通信し、頻繁な「光-電気-光」変換が不要になるため、大規模なAIタスクにおけるデータ転送がより速く、エネルギー消費が低く、モデルの訓練が「ストップ」しにくくなります。
簡単に言えば、Gemini 3は前世代モデルの微調整アップグレードではなく、完全に「ゼロから訓練された」大規模モデルシステムです。新しいハードウェアアーキテクチャ上に構築され、モデル構造と訓練プロセスが再設計されており、マルチモーダルな理解、より長いコンテキストウィンドウ、およびより強力な推論能力を実現しています。
なぜ投資家はGoogle TPUに大きな期待を寄せているのか?
Google TPUは、2つの重要なレベルでアップグレードを達成しました。
一、技術アーキテクチャの側面。
Gemini 3は「Mixture-of-Experts」(エキスパート混合)メカニズムを使用しており、単一の大規模モデルにすべてのタスクを任せるのではなく、多数の「エキスパートモデル」が分業します。各文、質問、またはタスクは、最も適切な「エキスパート」に割り当てられます。これにより、モデルは限られた計算能力でも効率的かつ賢く動作し、テキスト、画像、音声、ビデオなどのマルチモーダル情報を同時に理解し、より現実に近い理解を出力できます。
二、訓練プロセスの側面。
Gemini 訓練段階では3段階戦略を採用しています。
1. 初期学習段階 — 大量のマルチモーダル情報を通じて、AIに次の単語やコンテンツを予測させ、世界の常識を習得させます。
2. 専門的強化段階 — 人間が設計した問題(対話、質疑応答、推論など)で繰り返し訓練し、モデルが複雑なタスクを分解することを学ばせます。
3. フィードバック強化学習(RLHF)段階 — 人間とAIが協力して回答を採点し、継続的に改善することで、モデルが論理的推論や数学的証明などの高度な問題で進歩し続けます。
「Googleチェーン」:TPUとOCSを繋ぐ鍵
ここでOCS光交換技術に触れる必要があります。これはGoogle TPUアーキテクチャにおける最も重要なブレークスルーの一つであり、「Googleチェーン」(TPU + OCS深度融合システム)の技術的核でもあります。
AIモデルとデータセンターの規模が指数関数的に拡大するにつれて、数万個のチップとサーバーを協調させて計算する必要があります。従来の電気信号インターコネクトソリューションは、伝送遅延、高いエネルギー消費、複雑な配線の問題を引き起こし、建設コストを直接押し上げます。
「進化した」CPO(コパッケージドオプティクス)ソリューションは、光エンジンと交換チップを同じ基板に統合することで、電気-光信号変換効率を向上させました。一方、OCSはさらに進化し、光信号を介してチップとラックを直接接続し、頻繁な「光-電気-光」変換をキャンセルすることで、エネルギー消費と遅延を大幅に削減します。
SemiAnalysisのレポートによると、Google OCSカスタムネットワークは、ネットワークスループットを30%向上させ、消費電力を40%削減し、データフロー完了時間を10%短縮し、ネットワークダウンタイムを50倍削減し、資本支出コストを30%削減したとされています。
これが、TPUとOCS技術が深く結合して構成された高効率な計算ネットワークシステム、いわゆる「Googleチェーン」です。
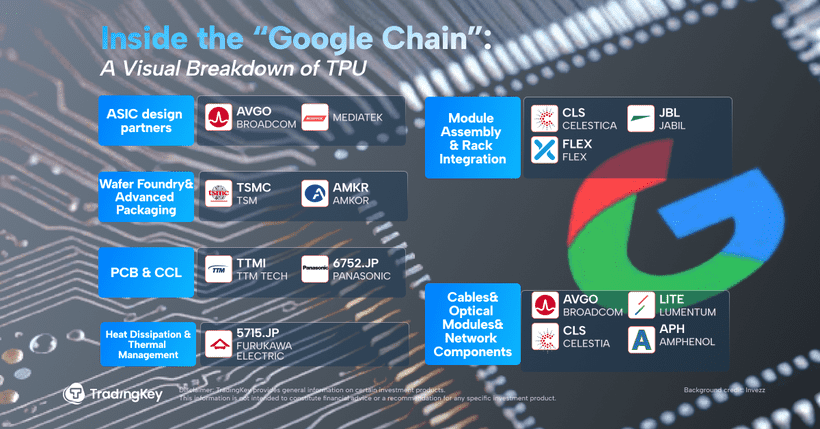
GoogleとBroadcom:AIハードウェアサプライチェーンの勝者
Google AIは、チップ(TPU)—ネットワーク(OCS)—モデル(Gemini)—アプリケーション(クラウドコンピューティング/検索/広告)を巡って、フルスタックの堀を築いています。
その中で、Google TPUコアとカスタムASICチップは、Broadcom(ブロードコム)との深い協力のもとで開発されています。Broadcomは設計に参加するだけでなく、SerDesインターフェースIP、高速インターコネクトチップ、および一部のシステム交換チップも提供しています。「Ironwood」TPUの大規模な商用展開に伴い、BroadcomのASIC事業収入は著しく増加しています。
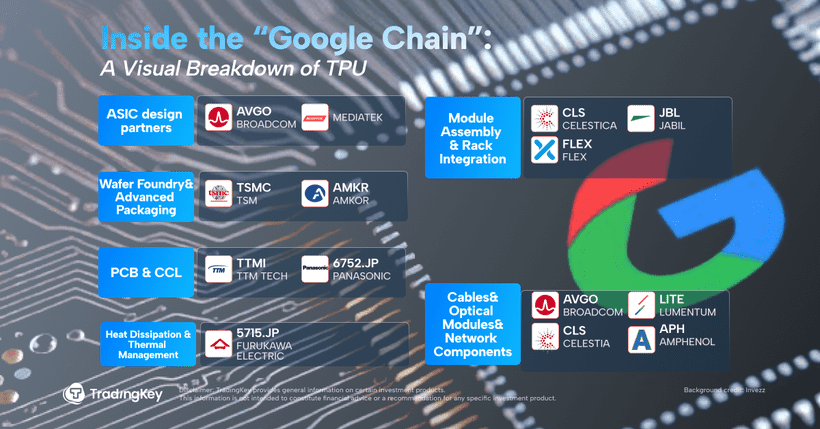
Celesticaは北米の主力ODM/EMSメーカーとして、TPU AIサーバーのマザーボードとラックのシステムインテグレーション、組み立て、テストを担当し、Google AIハードウェア展開の「ラストワンマイル」を担っています。Lumentumは光トランシーバーとOCS光スイッチに特化しており、Google AIクラスター「Apollo」光ネットワークシステムの主要サプライヤーの一つです。
この「Googleチェーンエコシステム」全体が、株価にも迅速に反映されています。Gemini 3の発表以来、Alphabetは連日大きく上昇し、Metaも同社と提携するというニュースが流れた後、さらに上昇幅を拡大しました。同時に、Broadcom(AVGO)、Celestica(CLS)、Lumentum Holdings(LITE)などもAlphabetとの協力から恩恵を受け、株価は二桁台の上昇を達成しています。
NVIDIAは焦っている
市場の不安に直面し、NVIDIAは対応に乗り出しました。木曜日、同社はXプラットフォームを通じて声明を発表し、「私たちはGoogleの成功を喜んでおり、このテック大手へのチップ提供を継続する予定です」と述べた後、すぐに付け加えて強調しました。
「NVIDIAは依然として業界を一代リードしており、現在、すべてのAIモデルを実行し、すべての計算能力シナリオをカバーできる唯一のプラットフォームです。」

NVIDIAがこれほど積極的に「市場を安心させる」のは初めてではありません。以前、著名な投資家Michael Burryは、AIブームを90年代後半のインターネットバブルになぞらえ、NVIDIAをバブル崩壊後に株価が暴落した当時のCiscoになぞらえました。
先週末、NVIDIAは異例にもアナリストに7ページにわたるメモを配布し、「バブル論」に正面から反論し、計算能力、ソフトウェア、エコシステムの3つの観点からBurryの意見に一つずつ反駁しました。しかし、市場の反応から見ると、この対応は成功しませんでした。アナリストは、このような大企業が非決算期に疑問に急いで対応することが、まさに「自信のなさ」を露呈していると評価しました。
言い換えれば、NVIDIAの今回の「進退窮まる」姿勢は、市場に元々潜んでいた恐れをかえって刺激してしまったのです。
結論
短期的には、NVIDIAが依然としてAI計算能力の王者の地位を堅守していることは間違いありません。しかし、より長期的には、産業の需要は「どちらか一方」ではないかもしれません。将来的には、カスタムASICとGPUは共存し、相互補完関係を形成する可能性があります。
結局のところ、AIの計算能力需要の増加は、技術ルートの変化によって止まることはありません。効率、コスト、そしてエコシステムの間でバランスを見つけられる者が、次の時代を定義し続けるでしょう。
本内容はAIによって翻訳されており、内容の正確性と明確性を確保するために確認を行っています。本情報は情報提供のみを目的としており、投資助言や推奨を行うものではありません。












コメント (0)
$ボタンをクリックし、シンボルを入力して、株式、ETF、またはその他のティッカーシンボルをリンクします。