

進入AI應用時代,CPU有望成爲下一個“存儲”機遇嗎?

在算力需求暴增的今天,CPU是否會重演PC時代崛起神話?這是一個值得思考的問題。如今,大模型推理、端側AI、智能物聯網正將計算壓力推向新的臨界點。英特爾、AMD股價悄然攀升,Arm架構異軍突起,甚至連蘋果、小米都在自研芯片中加大CPU投入。
這究竟是短暫的風口,還是結構性機遇的開始?當雲端集羣的CPU利用率逼近紅線,當每臺終端設備都需要獨立的AI推理能力,傳統處理器是否已經站在爆發的邊緣?
推理有望成爲重要方向
隨着AI應用從實驗室走向千行百業,推理計算正取代訓練成爲AI算力的主戰場。據IDC與浪潮信息聯合預測,2023年中國AI服務器工作負載中訓練端佔比58.7%,而到2027年推理端算力需求將飆升至72.6%。當大模型逐漸成熟,企業對算力的需求不再是砸錢堆疊訓練集羣,而是如何將模型高效、經濟地部署到真實業務場景中。這種轉變,讓CPU這一傳統通用處理器重新站在了舞臺中央。
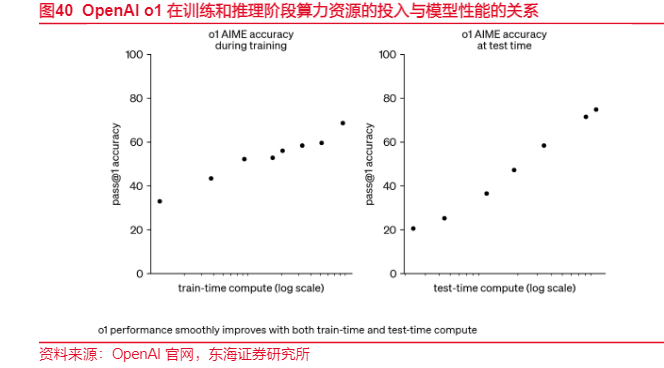
在推理場景中,CPU的性價比優勢正被重新發現。與動輒數十萬、功耗驚人的GPU相比,CPU在成本、可用性和總擁有成本(TCO)上展現出無可比擬的競爭力。英特爾數據顯示,使用CPU進行AI推理無需構建新的IT基礎設施,可複用既有平臺空閒算力,避免異構硬件帶來的管理複雜度。更重要的是,通過AMX加速、INT8量化優化等技術,現代CPU的推理性能已實現質的飛躍。實測表明,經過優化的至強處理器在ResNet-50等模型上推理速度提升可達8.24倍,精度損失不足0.17%。這種模式,正中中小企業下懷——它們不需要GPT-4級別的算力,但需要能跑通32B參數模型的經濟型方案。
CPU的用武之地,恰恰集中在AI推理的"長尾市場"。第一類是小語言模型(SLM)部署,如DeepSeek-R1 32B、Qwen-32B等模型,它們在企業級場景中文能力突出,參數規模適中,CPU完全能夠勝任。第二類是數據預處理與向量化環節,這類任務涉及文本清洗、特徵提取、嵌入生成等,天然適合CPU的串行處理能力。第三類是併發量高但單次計算簡單的"長尾"推理任務,如客服問答、內容審覈等,CPU可通過多核心並行處理數百個輕量級請求,實現更高的吞吐率。這些場景的共同點是:對延遲要求相對寬鬆,但對成本極度敏感,正是CPU大顯身手的舞臺。
2025年以來的許多上市公司已經將相關產品推向市場。浪潮信息(000977) 在3月率先推出元腦CPU推理服務器NF8260G7,搭載4顆英特爾至強處理器,通過張量並行和AMX加速技術,單機可高效運行DeepSeek-R1 32B模型,單用戶性能超20 tokens/s,同時處理20個併發請求。神州數碼(000034) 則在7月的WAIC大會上發佈KunTai R622 K2推理服務器,基於鯤鵬CPU架構,在2U空間內支持4張加速卡,主打"高性能、低成本"路線,瞄準金融、運營商等預算敏感型行業。這些廠商的佈局揭示了一個明確信號:CPU推理不是退而求其次,而是主動戰略選擇。
更深層的邏輯在於,AI算力正在走向"去中心化"和"場景化"。當每個工廠、每家醫院甚至每個手機都需要嵌入式推理能力時,不可能也不必要全部依賴GPU集羣。CPU作爲通用算力底座,能夠將AI能力無縫融入現有IT架構,實現"計算即服務"的平滑過渡。在這個意義上,CPU的確正在成爲AI時代的"新存儲":它不是最閃耀的,但卻是不可或缺的算力基礎設施。
CPU 可能比 GPU 更早成爲瓶頸
在Agent驅動的強化學習(RL)時代,CPU的瓶頸效應正以比GPU短缺更隱蔽卻更致命的方式浮現。與傳統單任務RL不同,現代Agent系統需要同時運行成百上千個獨立環境實例來生成訓練數據,這種"環境並行化"需求讓CPU成爲事實上的第一塊短板。
2025年9月,螞蟻集團開源的AWORLD框架將Agent訓練解耦爲推理/執行端與訓練端後,被迫採用CPU集羣承載海量環境實例,而GPU僅負責模型更新。這種架構選擇並非設計偏好,而是環境計算密集型的必然結果——每個Agent在與操作系統、代碼解釋器或GUI界面交互時,都需要獨立的CPU進程進行狀態管理、動作解析和獎勵計算,導致核心數直接決定了可同時探索的軌跡數量。
更深層的矛盾在於CPU-GPU pipeline的異步失衡。當CPU側的環境模擬速度無法匹配GPU的推理吞吐量時,policy lag(策略滯後)急劇惡化——GPU被迫空轉等待經驗數據,而Agent正在學習的策略與採集數據時的舊策略之間產生致命時差。這種滯後不僅降低樣本效率,更在PPO等on-policy算法中引發訓練震盪,甚至導致策略發散。智元機器人2025年3月開源的VideoDataset項目印證了這一點:其CPU軟件解碼方案成爲訓練瓶頸,切換到GPU硬件解碼後吞吐量提升3-4倍,CPU利用率才從飽和狀態回落。
2025年的工業級實踐進一步暴露了CPU瓶頸對收斂穩定性的系統性破壞。騰訊的AtlasTraining RL框架在萬億參數模型訓練中,不得不專門設計異構計算架構來協調CPU與GPU的協作,因其發現環境交互的隨機種子、CPU核心調度策略的微小差異,會通過早期學習軌跡的蝴蝶效應影響最終策略性能。更嚴峻的是,多智能體強化學習(MARL)的非平穩性加劇了這一問題——當數百個Agent策略同步更新時,CPU不僅要模擬環境,還需實時計算聯合獎勵、協調通信,這直接導致狀態空間複雜度呈指數級增長。
本質上,Agent RL將計算範式從"模型密集"轉向"環境密集",而CPU正是環境模擬的物理載體。當Agent需要探索工具使用、長鏈推理等複雜行爲時,每個環境實例都是一個小型操作系統,消耗1-2個CPU核心。此時,投入再多的A100或H200,若CPU核心數不足,GPU利用率仍會在30%以下徘徊,收斂時間從數週延長至數月。
2025年,這種瓶頸已從學術研究蔓延至產業實踐,解決CPU瓶頸已成爲RL infra的核心戰場。Agent時代的算力競賽,勝負手或許不在GPU的峯值算力,而在於能否用足夠的CPU核心餵飽那些飢餓的智能體。
相關文章
澳洲央行加息再度推升澳元走勢 2026年澳元匯率還會繼續上漲嗎?
TradingKey - 當全球主要經濟體仍在「減息競賽」中徘徊時,澳洲儲備銀行(RBA)在2026年2月投下了重磅炸彈,加息25個基點。這一逆勢而為的舉動徹底打亂了市場節奏。澳元(AUD)今年以來強勢上漲,延續了2025年的上行格局,2026年澳元匯率還會繼續上漲嗎?
比特幣的四年週期是否將於2026年失效?
比特幣四年週期是否已終結?在 2025 年打破歷史紀錄,成為減半後首個收跌的年份後,機構分析師正探討比特幣價格是否已與減半倒數脫鉤。本文分析現貨 ETF、全球流動性的影響,以及在 2026 年市場環境下邁向 2028 年減半的發展藍圖。
美元走勢預測:美元指數跌破 97.0 至 4 年新低,2026 年美元繼續下跌還是觸底反彈?
TradingKey - 2026年1月份,美元指數延續2025年的下跌走勢,正式跌破97.0關鍵關口,最低下探至95.5,創下自2022年2月以來的近4年新低。


