

‘Google Chain’ พลัง TPU ของ Google นำเทรนด์ตลาด



พอดแคสต์ AI
Alphabet กำลังท้าทายการครอบงำตลาด GPU ของ NVIDIA ด้วยแพลตฟอร์ม TPU ที่มีประสิทธิภาพสูง โดย Gemini 3 ซึ่งฝึกอบรมบน Ironwood TPUs รุ่นล่าสุด ผสานระบบ Optical Circuit Switching (OCS) เพื่อการสื่อสารที่เร็วขึ้นและใช้พลังงานน้อยลง การพัฒนานี้ทำให้นักลงทุนมองเห็นมูลค่าใหม่ใน AI stack ของ Alphabet ในขณะที่หุ้น NVIDIA เผชิญแรงกดดันจากการกังวลเรื่องภาวะตลาด AI ที่ร้อนแรงเกินไป แม้ NVIDIA จะยืนยันความเป็นผู้นำ แต่โครงสร้างพื้นฐาน AI ระยะยาวอาจเป็นการแข่งขันที่หลากหลายมากขึ้น โดย ASIC และ GPU อาจพัฒนาร่วมกันเพื่อตอบสนองความต้องการที่แตกต่างกัน
TradingKey - ขณะที่ความกังวลต่อภาวะตลาด AI ที่ร้อนแรงเกินไปได้ถ่วงน้ำหนักตลาด NVIDIA ซึ่งเคยเป็นสัญลักษณ์ความเชื่อมั่นของนักลงทุนในด้านการใช้จ่ายเทคโนโลยีขนาดใหญ่ กลับกลายเป็นหนึ่งในผู้ได้รับผลกระทบหนักที่สุด โดยราคาหุ้นเผชิญแรงกดดันและร่วงลง 12% ในเดือนนี้เพียงเดือนเดียว
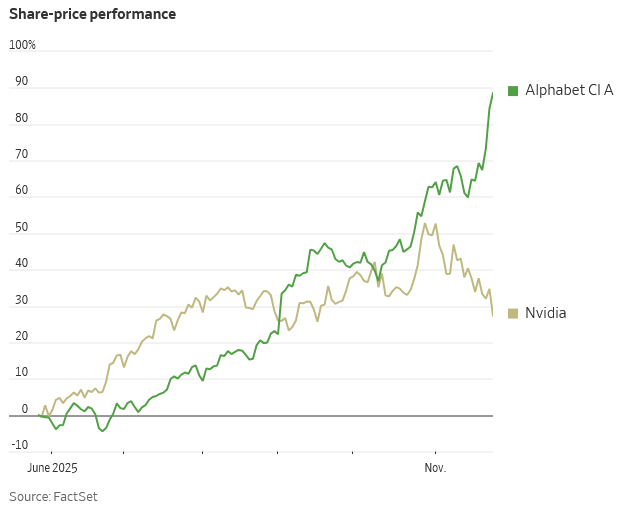
ขณะเดียวกัน Alphabet กำลังเคลื่อนไหวในทิศทางตรงกันข้าม โดยได้รับแรงหนุนจากความคืบหน้าของแพลตฟอร์ม TPU (Tensor Processing Unit) บริษัทแม่ของ Google ได้ผงาดขึ้นมาเป็นหนึ่งในไม่กี่ทางเลือกที่น่าเชื่อถือในการท้าทายการครอบงำตลาด GPU ของ NVIDIA ราคาหุ้นปรับตัวขึ้นกว่า 15% ในเดือนนี้ และนักลงทุนเริ่มมองว่า AI stack ของ Alphabet เป็นปัจจัยขับเคลื่อนมูลค่าใหม่ นักวิเคราะห์บางรายถึงกับคาดการณ์ว่า Alphabet อาจแซงหน้า Apple ขึ้นเป็นบริษัทที่มีมูลค่าสูงสุดเป็นอันดับสองของโลก
Gemini 3 ได้รับการฝึกอบรมโดยไม่พึ่ง NVIDIA ได้อย่างไร?
Gemini 3 ถูกสร้างขึ้นบนคลัสเตอร์ซูเปอร์คอมพิวเตอร์ TPU เจเนอเรชันล่าสุดของ Google โดยเฉพาะอย่างยิ่ง มันทำงานบน Ironwood TPUs แบบกำหนดเองของ Google ซึ่งเป็นชิปเจเนอเรชันที่ 7 ที่ให้ประสิทธิภาพเกือบ 10 เท่าของเจเนอเรชันก่อนหน้า คลัสเตอร์เหล่านี้เชื่อมต่อชิปหลายหมื่นตัวในเครือข่ายเมชสามมิติ ทำให้สามารถขยายขนาดได้อย่างมีประสิทธิภาพและรวมข้อมูลปริมาณมากได้ ซึ่งช่วยแก้ไขปัญหาคอขวดด้านการประมวลผลได้โดยตรง
สิ่งที่สำคัญคือ Ironwood ได้นำเสนอระบบการสื่อสารด้วยแสงอันทรงพลังที่เรียกว่า OCS (optical circuit switching) ซึ่งช่วยให้ TPUs สื่อสารกันได้โดยตรงผ่านสัญญาณแสง โดยขจัดกระบวนการแปลง "ไฟฟ้า-แสง-ไฟฟ้า" ซ้ำๆ ที่ต้องใช้พลังงานสูงและมีความหน่วงสูงภายใต้ปริมาณงานหนัก สำหรับการฝึกอบรมโมเดล AI ขนาดใหญ่ นั่นหมายถึงการไหลของข้อมูลที่เร็วขึ้น การใช้พลังงานที่ลดลง และการหยุดชะงักที่น้อยลงในระหว่างขั้นตอนที่ต้องใช้การประมวลผลอย่างเข้มข้น
กล่าวอีกนัยหนึ่ง Gemini 3 ไม่ใช่แค่เวอร์ชันที่ปรับปรุงจากรุ่นก่อนหน้า แต่เป็นโมเดลที่สร้างขึ้นใหม่ทั้งหมด โดยทำงานบนสถาปัตยกรรมฮาร์ดแวร์ใหม่ ใช้การออกแบบโมเดลที่ปรับปรุงใหม่ และได้รับการฝึกอบรมผ่านกระบวนการแบบครบวงจรเพื่อรองรับหน้าต่างบริบทที่ยาวขึ้น ความเข้าใจแบบหลายโมดอล และความสามารถในการให้เหตุผลที่ซับซ้อนยิ่งขึ้น
เหตุใดตลาดจึงกำหนดราคาความทะเยอทะยานด้าน TPU ของ Google ใหม่
Google's TPU stack ได้รับการปรับปรุงในสองมิติหลัก
ประการแรก ด้านสถาปัตยกรรม Gemini 3 ใช้กลยุทธ์ Mixture of Experts (MoE) โดยแบ่งงานออกเป็นโมเดลย่อยเฉพาะทาง แทนที่จะพึ่งพาทรานส์ฟอร์เมอร์แบบ monolithic เพียงตัวเดียว แต่ละประโยค คำถาม หรือข้อความค้นหาจะถูกส่งไปยัง "ผู้เชี่ยวชาญ" ที่เกี่ยวข้องมากที่สุด ทำให้โมเดลไม่เพียงแค่เร็วขึ้น แต่ยังฉลาดขึ้นเมื่อการประมวลผลขยายขนาด
แนวทางแบบกระจายนี้ยังช่วยเพิ่มประสิทธิภาพในรูปแบบต่างๆ ทั้งข้อความ รูปภาพ เสียง วิดีโอ และปรับผลลัพธ์ให้สอดคล้องกับความคาดหวังด้านการรับรู้ในโลกแห่งความเป็นจริงมากยิ่งขึ้น
ประการที่สอง ด้านกระบวนการฝึกอบรม Gemini 3 ใช้กระบวนการสามขั้นตอน:
① การฝึกอบรมเบื้องต้น (Pretraining) ด้วยข้อมูลหลายโมดอลที่หลากหลาย เพื่อสร้างสัญชาตญาณการคาดการณ์ทั่วไปสำหรับงานที่เกี่ยวกับคำถัดไปหรือเฟรมถัดไป; ② การเสริมแรง (Reinforcement) ผ่านงานที่มีโครงสร้าง เช่น การสนทนา, การให้เหตุผลเชิงตรรกะ และการแก้ปัญหา; ③ การปรับแต่ง (Fine-tuning) ผ่านข้อเสนอแนะรางวัลที่สอดคล้องกับมนุษย์ (RLHF) ซึ่งผู้ประเมินที่เป็น AI และมนุษย์จะให้คะแนนผลลัพธ์อย่างต่อเนื่อง ช่วยปรับปรุงการให้เหตุผลของโมเดลเมื่อเวลาผ่านไป
Google Stack = TPU + OCS
ความก้าวหน้าสำคัญในที่นี้คือเลเยอร์ OCS (Optical Circuit Switching) เป็นสิ่งที่เชื่อมโยงประสิทธิภาพชิปดิบของ TPU เข้ากับโครงสร้างการประมวลผล AI รูปแบบใหม่ และก่อให้เกิดแกนหลักของสิ่งที่บางคนเรียกว่า "Google Stack"
เมื่อโมเดล AI และปริมาณงานของศูนย์ข้อมูลขยายตัวอย่างทวีคูณ การสร้างโครงสร้างพื้นฐาน AI ที่ปรับขนาดได้นั้นจำเป็นต้องมีการเชื่อมต่อระหว่างชิปหลายพันตัวด้วยความเร็วสูง ต้นทุนต่ำ และความหน่วงต่ำ ระบบสวิตชิ่งไฟฟ้าแบบดั้งเดิมทำให้เกิดความหน่วง ความร้อน ความซับซ้อนของสายเคเบิล และการสิ้นเปลืองพลังงาน ซึ่งทั้งหมดนี้ล้วนผลักดันให้ต้นทุนต่อวัตต์และต้นทุนต่อการสอบถามสูงขึ้น
การออกแบบ CPO (co-packaged optics) ช่วยได้โดยนำเอ็นจิ้นออปติคอลมาไว้ใกล้กับซิลิคอนสวิตชิ่งมากขึ้น แต่ OCS ก้าวไปอีกขั้นด้วยการสวิตชิ่งด้วยแสงแบบเต็มรูปแบบข้ามแร็คและบอร์ดในระดับโครงสร้าง โดยไม่มีชั้นการแปลงใดๆ อยู่ระหว่างกลาง
จากข้อมูลของบริษัทวิเคราะห์เซมิคอนดักเตอร์ SemiAnalysis เครือข่าย OCS แบบกำหนดเองของ Google ช่วยเพิ่มปริมาณงานเครือข่ายโดยรวมถึง 30% ลดการใช้พลังงาน 40% ลดเวลาการไหลของข้อมูลให้สั้นลง 10% ลดเวลาหยุดทำงานของเครือข่ายลง 50 เท่า และลดค่าใช้จ่ายในการลงทุนลง 30%
การผสานรวมอย่างแน่นแฟ้นระหว่าง TPU และระบบออปติกนี้เอง ที่เป็นตัวกำหนด "Google Stack" ใหม่ ซึ่งเป็นโครงสร้างการประมวลผลที่ออกแบบมาสำหรับงาน AI เป็นหลัก
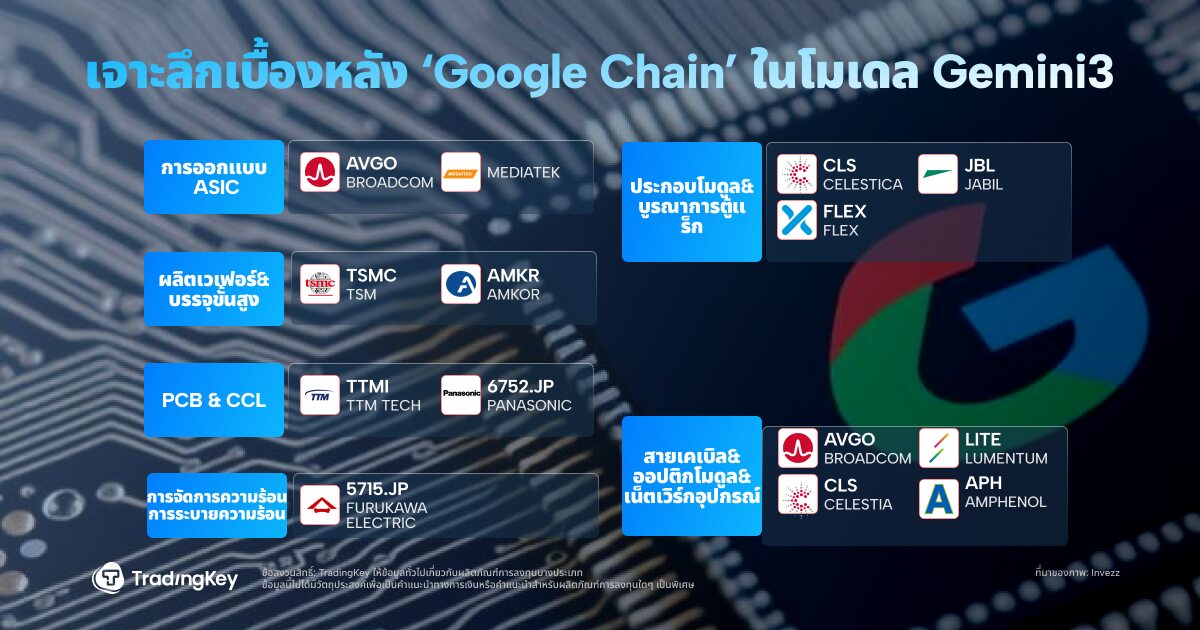
ห่วงโซ่อุปทานฮาร์ดแวร์เบื้องหลัง AI Stack ของ Google
คูเมือง AI ของ Google ตอนนี้ครอบคลุมตั้งแต่ชิปไปจนถึงโมเดลและคลาวด์ ห่วงโซ่คุณค่าแบบฟูลสแต็คมีลักษณะดังนี้: การประมวลผล (สถาปัตยกรรม Custom TPU) + การเชื่อมต่อ (ระบบสวิตช์ออปติคอล OCS) + โมเดล (ซีรีส์ Gemini 3) + แอปพลิเคชัน (การค้นหา, Cloud APIs และโฆษณา)
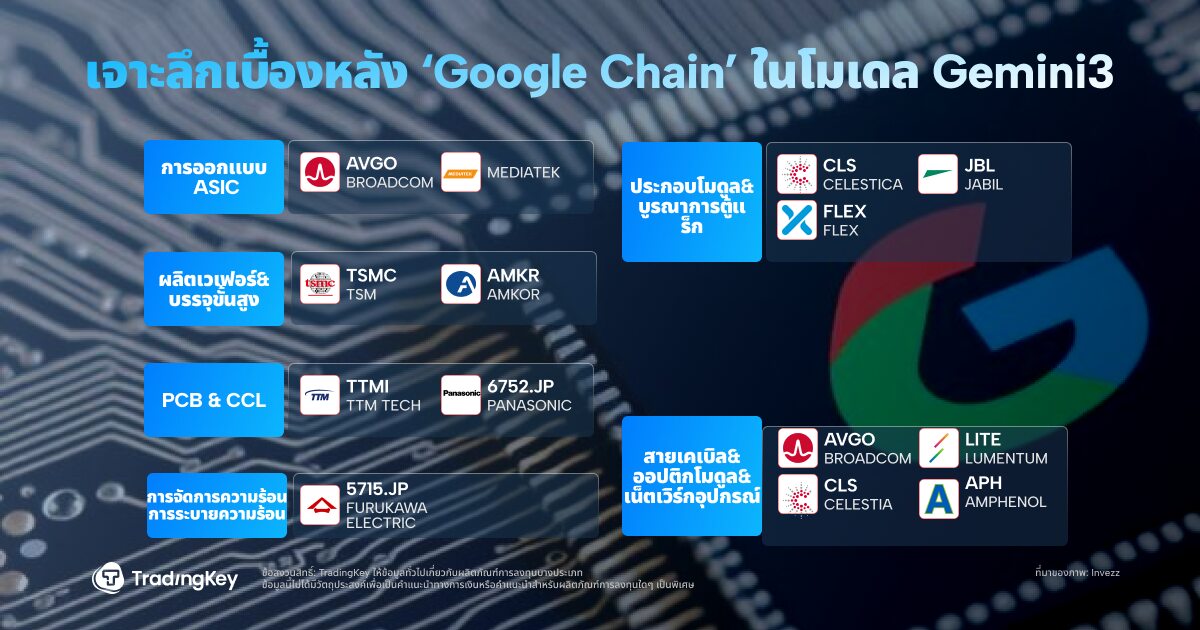
ในด้านฮาร์ดแวร์ Broadcom มีบทบาทสำคัญ บริษัทร่วมออกแบบคอร์ ASIC ของ Google รวมถึง SerDes IP และโมดูลเชื่อมต่อ ด้วยการผลิต Ironwood ที่กำลังดำเนินอยู่ รายได้ ASIC ของ Broadcom จึงเห็นแนวโน้มขาขึ้นที่มีนัยสำคัญ
Celestica ซึ่งเป็นผู้จำหน่าย EMS/ODM รายใหญ่ในอเมริกาเหนือ รับผิดชอบการรวมบอร์ดและแร็คระดับระบบ การประกอบ และการทดสอบ ซึ่งเป็นการส่งมอบ "ขั้นตอนสุดท้าย" ของการปรับใช้เซิร์ฟเวอร์ AI ของ Google
Lumentum จัดหาตัวรับส่งสัญญาณออปติคอลและส่วนประกอบ OCS ที่สำคัญ อุปกรณ์ของบริษัทเป็นหัวใจสำคัญของระบบคลัสเตอร์ที่เชื่อมต่อด้วยแสงขนาดดาต้าเซ็นเตอร์ "Apollo" ของ Google
ทั้งหมดนี้เริ่มสะท้อนให้เห็นในราคาหุ้น นับตั้งแต่การเปิดตัว Gemini 3 หุ้นของ Alphabet ได้ปรับตัวขึ้นอย่างแข็งแกร่ง หลังจากมีรายงานว่า Meta อาจร่วมมือกับ Google ในโครงสร้างพื้นฐานที่ขับเคลื่อนด้วย TPU การปรับตัวขึ้นก็ยิ่งขยายวงกว้างออกไป ชื่อที่เกี่ยวข้อง เช่น Broadcom (AVGO), Celestica (CLS) และ Lumentum (LITE) ก็ทำกำไรได้เป็นตัวเลขสองหลักเช่นกัน
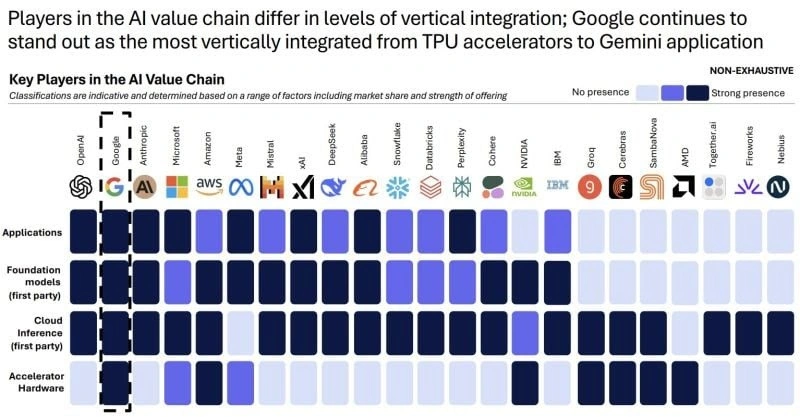
NVIDIA ตอบสนอง—แต่ตลาดไม่เชื่อเต็มที่
NVIDIA ได้ดำเนินการที่ไม่ปกติด้วยการแสดงความคิดเห็นต่อสาธารณะ
ในแถลงการณ์ที่โพสต์บน X (เดิมคือ Twitter) บริษัทได้แสดงความยินดีกับ Google และกล่าวว่ามีแผนที่จะ "ยังคงจัดหาชิปให้กับพันธมิตรที่มีคุณค่ารายนี้ต่อไป" แต่ก็เน้นย้ำว่า:
"NVIDIA ยังคงนำหน้าคู่แข่งเต็มหนึ่งเจเนอเรชัน และเป็นแพลตฟอร์มเดียวที่สามารถรันโมเดล AI ขนาดใหญ่ทุกรุ่นในระดับสเกลได้"

ไม่ใช่ครั้งแรกที่ NVIDIA พยายามปลอบขวัญความกังวลของตลาด หลังจากที่นักลงทุน Michael Burry เปรียบเทียบความเฟื่องฟูของ AI กับฟองสบู่อินเทอร์เน็ตช่วงปลายทศวรรษ 1990 และเปรียบเทียบ NVIDIA กับ Cisco ก่อนเกิดวิกฤต บริษัทได้ดำเนินการที่ไม่ค่อยมีใครทำ นั่นคือการเผยแพร่บันทึกภายใน 7 หน้าเพื่อโต้แย้งข้อกล่าวอ้างของ Burry ในด้านการประมวลผล, ซอฟต์แวร์ และระบบนิเวศ
แต่ความพยายามดังกล่าวอาจส่งผลเสีย
นักวิเคราะห์บางรายตั้งข้อสังเกตว่าการตอบสนองเชิงรับเช่นนี้ โดยเฉพาะอย่างยิ่งในช่วงสัปดาห์ที่ไม่มีการประกาศผลประกอบการ "อาจเผยให้เห็นความตื่นตระหนกมากกว่าความมั่นใจ"
กล่าวอีกนัยหนึ่ง: NVIDIA ดูเหมือนตื่นตระหนก และเพียงแค่นั้นก็อาจตอกย้ำความกังวลที่มีอยู่ของนักลงทุน
สรุป
เป็นที่ชัดเจนว่า ในระยะสั้น NVIDIA ยังคงควบคุมระบบนิเวศการประมวลผล AI ที่เน้น GPU ไว้อย่างมั่นคง โดยไม่มีคู่แข่งที่ท้าทายตำแหน่งผู้นำในระยะใกล้
แต่ในระยะยาว โครงสร้างพื้นฐาน AI อาจไม่ใช่การแข่งขันที่ผู้ชนะกวาดเรียบ
ASIC ที่สร้างขึ้นเอง เช่น TPU ของ Google และ GPU ทั่วไป เช่นของ NVIDIA อาจพัฒนาไปสู่โครงสร้างที่เสริมกันและเฉพาะเจาะจงกับงาน โดยแต่ละอย่างอาจตอบสนองความต้องการที่แตกต่างกันไป ขึ้นอยู่กับประเภทของปริมาณงาน โปรไฟล์ต้นทุน และเป้าหมายการเพิ่มประสิทธิภาพ
สิ่งที่ไม่อาจปฏิเสธได้คือแนวโน้มนี้เอง: ความต้องการ AI ไม่ได้ลดลง ความต้องการด้านการประมวลผลจะเพิ่มขึ้นเท่านั้น ไม่ว่าสถาปัตยกรรมใดจะประสบความสำเร็จสูงสุดก็ตาม
บทความแนะนำ











ความคิดเห็น (0)
คลิกปุ่ม $ ป้อนสัญลักษณ์ และเลือกเพื่อเชื่อมโยงหุ้น, กองทุน ETF หรือสัญลักษณ์หลักทรัพย์อื่น ๆ