

Google’s TPU-Powered ‘Google Chain’ Leads Market Trends

TradingKey - As concerns about an overheated AI trade weigh on markets, NVIDIA has become one of its biggest casualties. Once seen as a symbol of investor confidence in large-scale technology spending, the company’s stock is now under pressure—down 12% this month alone.
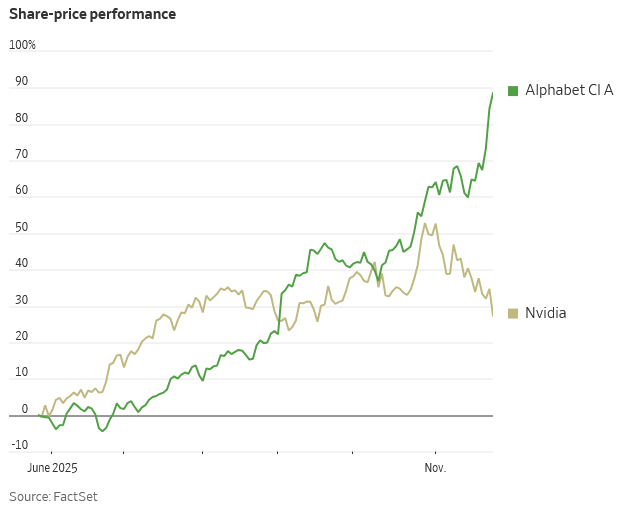
Meanwhile, Alphabet is moving in the opposite direction. Bolstered by progress on its TPU (Tensor Processing Unit) platform, Google’s parent company has emerged as one of the few credible alternatives to NVIDIA’s GPU dominance. Shares are up over 15% month-to-date—and investors are beginning to view Alphabet's AI stack as a new valuation driver. Some analysts are even speculating Alphabet could surpass Apple as the world’s second most valuable company.
How Was Gemini 3 Trained Without NVIDIA?
Gemini 3 was built entirely on Google’s latest-generation TPU supercomputing clusters. Specifically, it runs on Google’s custom Ironwood TPUs—7th-generation chips that deliver nearly 10x the performance of the prior generation. These clusters connect tens of thousands of chips in three-dimensional mesh networks, enabling efficient scaling and high-volume aggregation—directly addressing compute bottlenecks.
Crucially, Ironwood introduces a powerful optical communication system known as OCS (optical circuit switching). This enables TPUs to communicate via light signals directly—eliminating the energy- and latency-intensive process of repeated “electrical–optical–electrical” conversions under heavy loads. For large-scale AI model training, that means faster data flows, lower energy use, and fewer stalls during compute-intensive stages.
In other words, Gemini 3 isn’t just a refined version of its predecessor—it’s a model built from scratch. It runs on a new hardware architecture, uses re-engineered model designs, and was trained through an end-to-end process to support longer context windows, multimodal understanding, and more advanced reasoning capacities.
Why the Market Is Repricing Google’s TPU Ambitions
Google’s TPU stack has improved along two key dimensions.
First, on architecture. Gemini 3 employs a Mixture of Experts (MoE) strategy—dividing tasks across specialized sub-models instead of relying on one monolithic transformer. Each sentence, question, or query gets routed to the most relevant “expert,” making the model not just faster but smarter as compute scales.
This distributed approach also boosts efficiency across modalities—text, images, speech, video—and aligns outputs more closely with real-world cognitive expectations.
Second, on training flow. Gemini 3 uses a three-stage pipeline:
① Pretraining on diverse multimodal data to build general predictive intuition for next-word or next-frame tasks; ②Reinforcement via structured tasks such as dialogue, logical reasoning, and problem-solving; ③ Fine-tuning via human-aligned reward feedback (RLHF), where AI and human evaluators score outputs continuously, improving model reasoning over time.
Google Stack = TPU + OCS
The breakthrough here is the OCS (Optical Circuit Switching) layer. It’s what connects the raw chip performance of TPU to a new kind of AI-compute fabric—and forms the backbone of what some are now calling the “Google Stack.”
As AI models and data center workloads balloon exponentially, building scalable AI infrastructure requires high-speed, low-cost, low-latency interconnects between thousands of chips. Traditional electrical switching systems bring latency, heat, cable complexity, and energy drag—all of which drive up cost per watt and cost per query.
CPO (co-packaged optics) designs help, by bringing optical engines closer to switching silicon. But OCS goes a step further: full optical switching across racks and boards at the fabric level—no conversion layers in between.
According to semiconductor analysis firm SemiAnalysis, Google's customized OCS network increased its overall network throughput by 30%, reduced power consumption by 40%, shortened data flow completion time by 10%, reduced network downtime by 50 times, and reduced capital expenditure by 30%.
It's this tight meld between TPU and optics that defines the new “Google Stack”—a compute substrate designed around AI-to-the-core workloads.
The Hardware Supply Chain Behind Google’s AI Stack
Google’s AI moat now extends from chip to model to cloud. The full-stack value chain looks like this: Compute (Custom TPU architecture)+Interconnect (OCS optical switch systems)+Model:(Gemini 3 series)+Application:((Search, cloud APIs, and advertising.)
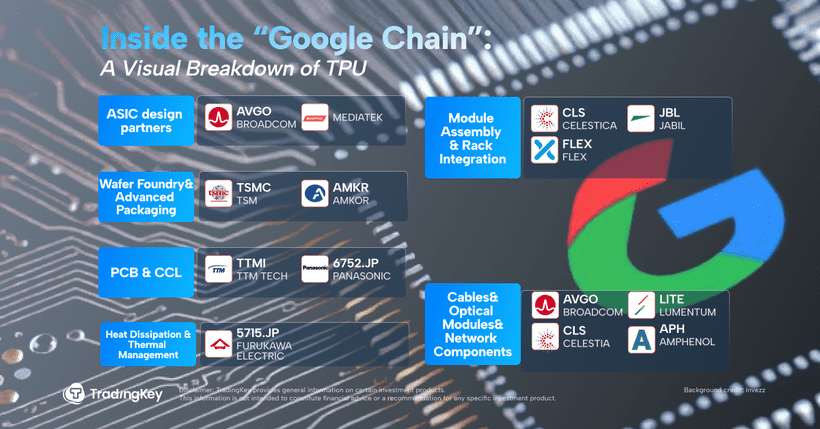
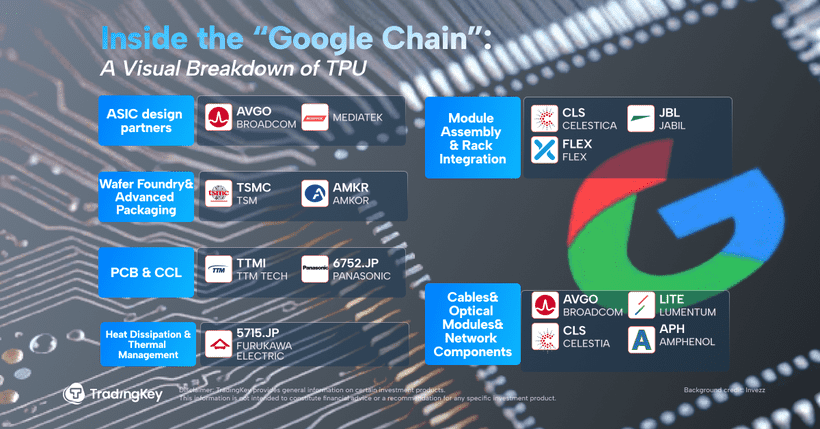
On the hardware side, Broadcom plays a central role. The company co-designs Google’s ASIC cores, including SerDes IP and interconnect modules. With Ironwood in production, Broadcom’s ASIC revenue is seeing meaningful upside.
Celestica, a major EMS/ODM vendor in North America, handles system-level board and rack integration, assembly, and testing—delivering the “last mile” of Google’s AI server deployments.
Lumentum supplies critical optical transceivers and OCS components. Its gear sits at the heart of Google’s “Apollo” datacenter-scale light-linked cluster systems.
All this is starting to show up in stock prices. Since the launch of Gemini 3, shares of Alphabet have rallied sharply. After reports that Meta may collaborate with Google on TPU-powered infrastructure, the rally has extended. Related names—Broadcom (AVGO), Celestica (CLS), and Lumentum (LITE)—have also posted double-digit gains.
NVIDIA Responds—But the Market Isn’t Fully Buying It
NVIDIA took the unusual step of commenting publicly.
In a statement posted on X (formerly Twitter), the company congratulated Google and said it plans to “continue supplying chips to this valued partner.” But it also emphasized that:
“NVIDIA remains one full generation ahead of competition—and is the only platform capable of running every major AI model at scale.”

It’s not the first time NVIDIA has tried to calm market nerves.
After investor Michael Burry likened the AI boom to the late-1990s internet bubble—and compared NVIDIA to a pre-crash Cisco—the company took a rare step: distributing a 7-page internal memo rebutting Burry’s claims across compute, software, and ecosystem dimensions.
But the effort may have backfired.
Some analysts noted that such a defensive response—especially during a non-earnings week—“may reveal more alarm than reassurance.”
In other words: NVIDIA looked rattled. And that alone may have reinforced investors’ existing anxieties.
Conclusion
It’s clear that, in the short term, NVIDIA remains firmly in control of the GPU-centered AI compute ecosystem, with no near-term challenger to its leadership position.
But over the longer term, AI infrastructure may not be a winner-takes-all contest.
Custom-built ASICs—like Google’s TPUs—and general-purpose GPUs—like NVIDIA’s—could evolve into a complementary, task-specific structure. Each may serve different needs depending on workload type, cost profile, and performance optimization goals.
What’s not in doubt is the trend itself: AI demand isn’t retreating. Compute requirements will only grow—regardless of which architecture ends up on top.
Recommended Articles












Comments (0)
Click the $ button, enter the symbol, and select to link a stock, ETF, or other ticker.