

การวิจัยแสดงให้เห็นว่าโมเดล AI เชี่ยวชาญความสามารถมานานก่อนที่จะจัดแสดง

Havard และมหาวิทยาลัยมิชิแกนไม่ใช่คนแรกที่พยายามทำความเข้าใจความสามารถของโมเดล AI โดยนักวิจัยจาก Anthropic เปิดเผยบทความเรื่อง 'การเรียนรู้พจนานุกรม' บทความนี้กล่าวถึงการเชื่อมโยงในภาษาของ Claude กับแนวคิดเฉพาะที่เข้าใจ แม้ว่างานวิจัยเหล่านี้ส่วนใหญ่จะมีมุมมองที่แตกต่างกัน แต่หลักๆ แล้วคือการทำความเข้าใจโมเดล AI Anthropic เปิดเผยว่าพบคุณลักษณะต่างๆ ที่อาจเชื่อมโยงกับแนวคิดที่สามารถตีความได้ต่างๆ “เราพบคุณลักษณะนับล้านที่ดูเหมือนจะสอดคล้องกับแนวคิดที่สามารถตีความได้ ตั้งแต่วัตถุที่เป็นรูปธรรม เช่น ผู้คน ประเทศ และอาคารที่มีชื่อเสียง ไปจนถึง trac แนวคิด เช่น อารมณ์ สไตล์การเขียน และขั้นตอนการใช้เหตุผล” การวิจัยเปิดเผย ในระหว่างการวิจัย นักวิจัยได้ทำการทดลองหลายครั้งโดยใช้แบบจำลองการแพร่กระจาย ซึ่งเป็นหนึ่งในสถาปัตยกรรมที่ได้รับความนิยมมากที่สุดสำหรับ AI ในระหว่างการทดลอง พวกเขาตระหนักว่าแบบจำลองมีวิธีที่แตกต่างกันในการจัดการกับแนวคิดพื้นฐาน รูปแบบมีความสอดคล้องกันเนื่องจากโมเดล AI แสดงความสามารถใหม่ในระยะต่างๆ และจุดเปลี่ยนที่ชัดเจนที่ส่งสัญญาณเมื่อได้รับความสามารถใหม่ ในระหว่างการฝึกอบรม แบบจำลองแสดงให้เห็นว่าพวกเขาเชี่ยวชาญแนวคิดประมาณ 2,000 ขั้นตอนเร็วกว่าที่การทดสอบมาตรฐานจะตรวจพบ แนวคิด S tron g ปรากฏประมาณ 6,000 ขั้น และขั้นที่อ่อนแอกว่าปรากฏประมาณ 20,000 ขั้น หลังจากที่ปรับสัญญาณแนวคิดแล้ว พวกเขาค้นพบความสัมพันธ์โดยตรงกับความเร็วในการเรียนรู้ นักวิจัยใช้วิธีการกระตุ้นทางเลือกเพื่อเปิดเผยความสามารถที่ซ่อนอยู่ก่อนที่จะแสดงในการทดสอบมาตรฐาน ลักษณะการซ่อนเร้นที่เกิดขึ้นอย่างแพร่หลายมีผลกระทบต่อการประเมินและความปลอดภัยของ AI ตัวอย่างเช่น การวัดประสิทธิภาพแบบดั้งเดิมอาจพลาดความสามารถบางอย่างของโมเดล AI ดังนั้นจึงขาดทั้งประโยชน์และความสามารถที่เกี่ยวข้อง ในระหว่างการวิจัย ทีมงานได้ค้นพบวิธีการบางอย่างในการเข้าถึงความสามารถที่ซ่อนอยู่ของโมเดล AI การวิจัยนี้เรียกว่าวิธีการแทรกแซงแบบแฝงเชิงเส้นและการกระตุ้นมากเกินไป เนื่องจากนักวิจัยได้สร้างแบบจำลองแสดงพฤติกรรมที่ซับซ้อนก่อนที่จะแสดงในการทดสอบมาตรฐาน นักวิจัยยังค้นพบว่าโมเดล AI จัดการคุณสมบัติที่ซับซ้อนบางอย่างก่อนที่จะแสดงผ่านการแจ้งเตือนมาตรฐาน ตัวอย่างเช่น โมเดลอาจได้รับแจ้งให้สร้าง 'ผู้หญิงยิ้ม' หรือ 'ผู้ชายสวมหมวก' ได้สำเร็จ ก่อนที่จะถูกขอให้รวมเข้าด้วยกัน อย่างไรก็ตาม การวิจัยแสดงให้เห็นว่าพวกเขาได้เรียนรู้ที่จะรวมมันเข้าด้วยกันตั้งแต่เนิ่นๆ แต่จะไม่สามารถแสดงออกมาผ่านคำแนะนำแบบเดิมๆ ได้ โมเดลที่แสดงความสามารถอาจกล่าวได้ว่าเป็นโมเดลที่โหดเหี้ยม ซึ่งเป็นสถานการณ์ที่โมเดลแสดงประสิทธิภาพการทดสอบที่สมบูรณ์แบบหลังจากการฝึกอบรมที่ยาวนาน อย่างไรก็ตาม นักวิจัยกล่าวว่ามีความแตกต่างที่สำคัญระหว่างทั้งสองอย่าง แม้ว่าการบ่นจะเกิดขึ้นหลังจากการฝึกอบรมหลายครั้งและเกี่ยวข้องกับการปรับปรุงการกระจายชุดข้อมูลเดียวกันหลายชุด แต่การวิจัยแสดงให้เห็นว่าความสามารถเหล่านี้เกิดขึ้นระหว่างการเรียนรู้เชิงรุก นักวิจัยตั้งข้อสังเกตว่าแบบจำลองเหล่านี้พบวิธีใหม่ในการจัดการแนวคิดผ่านการเปลี่ยนแปลงในระยะต่างๆ มากกว่าการปรับปรุงการเป็นตัวแทนอย่างค่อยเป็นค่อยไปใน grokking จากการวิจัยพบว่าโมเดล AI รู้แนวคิดเหล่านี้ แต่ไม่สามารถแสดงออกมาได้ คล้ายกับคนดูและเข้าใจหนังต่างประเทศแต่พูดภาษาไม่ได้ นี่แสดงให้เห็นว่าโมเดลส่วนใหญ่มีความสามารถมากกว่าที่แสดง และยังแสดงให้เห็นถึงความยากลำบากในการทำความเข้าใจและการควบคุมความสามารถด้วย จากศูนย์ถึง Web3 Pro: แผนเปิดตัวอาชีพ 90 วันของคุณ การวิจัยแสดงให้เห็นว่าแบบจำลอง AI อยู่ภายในแนวคิด
นักวิจัยเปิดเผยวิธีการเข้าถึงความสามารถที่ซ่อนอยู่
บทความที่เกี่ยวข้อง
RBA ปรับขึ้นอัตราดอกเบี้ยหนุนค่าเงินดอลลาร์ออสเตรเลียอีกครั้ง: ค่าเงินดอลลาร์ออสเตรเลียจะปรับตัวสูงขึ้นอย่างต่อเนื่องในปี 2026 หรือไม่?
TradingKey - ในขณะที่กลุ่มประเทศเศรษฐกิจหลักของโลกยังคงตกอยู่ท่ามกลาง "การแข่งขันปรับลดอัตราดอกเบี้ย" ธนาคารกลางออสเตรเลีย (RBA) ได้สร้างความประหลาดใจครั้งใหญ่ในเดือนกุมภาพันธ์ 2026 ด้วยการปรับขึ้นอัตราดอกเบี้ย 25 basis points การเคลื่อนไหวที่สวนทางกับแนวโน้มนี้ได้ส่งผลกระทบต่อจังหวะของตลาดอย่างสิ้นเชิง โดยค่าเงินดอลลาร์ออสเตรเลีย (AUD) ได้ปรับตัวแข็งค่าขึ้นอย่างรุนแรงตั้งแต่ต้นปีที่ผ่านมา ซึ่งเป็นการขยายตัวต่อเนื่องจากแนวโน้มขาขึ้นในปี 2025 ทั้งนี้ อัตราแลกเปลี่ยน AUD จะยังคงปรับตัวสูงขึ้นต่อเนื่องตลอดทั้งปี 2026 หรือไม่?
ผลกระทบจากการเดิมพันในสนามเลือกตั้งของซานาเอะ ทากาอิจิจะเป็นอย่างไร? ค่าเงินเยนจะดีดตัวขึ้นหรือร่วงลง?
TradingKey - บทเปิดฉากของปี 2026 เริ่มต้นขึ้นด้วยความร้อนแรงเกินกว่าที่วอลล์สตรีทคาดการณ์ไว้ ท่ามกลางระยะเวลาที่เหลืออีกเพียงไม่กี่วันก่อนถึงการเลือกตั้งสภาผู้แทนราษฎรญี่ปุ่นในวันที่ 8 กุมภาพันธ์ นายกรัฐมนตรีซานาเอะ ทาคาอิจิ ผู้ดำรงตำแหน่งปัจจุบัน กำลังเดิมพันครั้งใหญ่ที่สุดในเส้นทางอาชีพการเมืองของเธอ
3 แผนภูมิสะท้อนภาพการเปลี่ยนแปลงของราคาทองคำและเงิน
TradingKey - ราคาทองคำและเงินฟื้นตัวขึ้นในวันพุธหลังจากถูกเทขายอย่างหนักเมื่อสัปดาห์ที่แล้ว โดยนักลงทุนในกลุ่มโลหะมีค่าดังกล่าวยังคงมีความเชื่อมั่น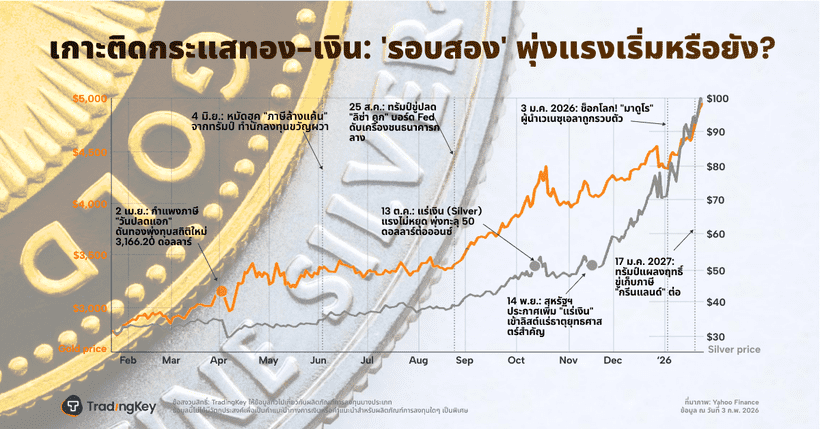
ราคาทองคำและเงินฟื้นตัวอย่างแข็งแกร่ง: การฟื้นตัวในระยะสั้นหรือจุดเริ่มต้นของตลาดขาขึ้นรอบใหม่?
TradingKey - โลหะมีค่าดีดตัวกลับอย่างแข็งแกร่งหลังความผันผวนอย่างรุนแรง ในขณะที่ตลาดกำลังเผชิญกับการเลือกทิศทางที่สำคัญ หลังจากปรับตัวลดลงอย่างหนักติดต่อกันสองวัน ตลาดโลหะมีค่าได้กลับมาฟื้นตัวอย่างแข็งแกร่งในวันอังคารนี้ โดยเมื่อวันที่ 3 สัญญาซื้อขายทองคำและเงินล่วงหน้าในตลาดนิวยอร์กปิดตลาดพุ่งสูงขึ้นอย่างมีนัยสำคัญ ส่งผลให้บรรยากาศการลงทุนปรับตัวดีขึ้นอย่างเห็นได้ชัด นักลงทุนกำลังประเมินความตื่นตระหนกที่เกิดขึ้นก่อนหน้านี้จากปัจจัยทางนโยบายใหม่ และกำลังมองหาโอกาสในการเข้าซื้อเมื่อราคาอ่อนตัว (buy-the-dip) อย่างคึกคัก
ราคาทองคำแตะระดับ 5,000 ดอลลาร์ ราคาเงินพุ่งทะลุ 100 ดอลลาร์ ใครอยู่เบื้องหลัง “ภาวะการแห่ซื้ออย่างบ้าคลั่ง” ในครั้งนี้?
TradingKey — ในช่วงเช้าของการซื้อขายวันจันทร์ ราคาทองคำสปอตพุ่งทะลุระดับ 5,000 ดอลลาร์ต่อออนซ์เป็นประวัติการณ์ ซึ่งเป็นความสำเร็จที่เกิดขึ้นเพียงสามเดือนกว่าหลังจากราคาพุ่งเกินระดับ 4,000 ดอลลาร์เป็นครั้งแรกเมื่อวันที่ 8 ตุลาคม 2025 ในช่วงเวลาเดียวกัน ราคาสปอตเงินยังได้ปรับตัวเพิ่มขึ้นอย่างแข็งแกร่งจนทำระดับสูงสุดใหม่ที่ 106 ดอลลาร์ต่อออนซ์
