銅から光へ:ルメンタム(LITE)――AI時代の「光の中枢」



AIポッドキャスト
AIデータセンターにおける銅配線の物理的限界から、光インターコネクトへの移行が加速している。NvidiaはLumentumに20億ドルを出資し、CPO(共同パッケージ光技術)やNVLink光インターコネクトの光源となるInPレーザーを確保した。LumentumはInPウェハー製造から光モジュール、OCSシステムまで垂直統合を進め、EMLレーザーチップ、CPO用CWレーザー、OCSシステム、クラウド光モジュールという4つの成長エンジンを持つ。同社は売上高、粗利益率、営業利益率、EPSの全てで顕著な改善を示しており、AI光インターコネクト市場における主要プレーヤーとしての地位を確立しつつある。ただし、バリュエーションの高さ、技術経路の不確実性、顧客集中度、競争激化といったリスク要因も存在する。

前回のAI強気相場の主役がGPUだったとすれば、今回のスポットライトは静かにオプティクスへと移っている。真の問いは、もはやNvidiaを買い続けるべきかどうかではなく、次のようなものだ。NVLinkやGPUを支える光インターコネクト・チェーン全体において、次に純粋に恩恵を受けるのは誰か?
過去2週間にわたり、Jensen Huang氏自らが一つの答えを指し示している。それはLumentumだ。
3月2日、Nvidiaは40億ドルを投じ、LumentumとCoherentにそれぞれ20億ドルを出資した。また、優先的な生産枠の確保を条件とした数年間にわたる大規模な購入契約を締結した。これは単なる財務投資ではなく、AI工場の最も重要かつ希少なリソースである、CPOや将来のNVLink光インターコネクトの光源となるInPレーザーを、一握りのサプライヤーの手に実質的に囲い込むものである。Lumentumはその中で最も純粋な関連銘柄と言える。同社は上流のInPウェハー工場を所有し、中流でEMLやCW/ELSレーザーを製造し、下流ではOCSやクラウド向け光モジュールも手掛けているからだ。
タイミングも極めて絶妙だ。来週、一方でサンノゼではNvidiaのGTC 2026が開催され、次世代アーキテクチャやNVLinkの継続的な拡張計画、そしてCPOがいつ本格的に量産体制に入るかが明確にされる。もう一方では、光通信における世界で最も重要な国際会議であるOFCが開催され、光モジュール、CPO、OCSのあらゆるベンダーが同じ週にロードマップを提示することになる。コンピューティングの演算会議と光インターコネクトの展示会がこれほど密接に衝突するのは初めてのことであり、Lumentumはこの2つの主要なストーリーの交差点に位置している:片方の手にはNvidiaからの20億ドルの提携と長期受注を握り、もう一方の手ではCPO光源やOCSといった主要なリンクを支配している。多くの機関投資家にとって、同社はこの光インターコネクト・チェーンにおいて最も象徴的な企業の一つとなっている。すべてのプレーヤーの中で、なぜLumentumがこの分野で最も中心的な地位を占めるに至ったのか。
銅の物理的限界:見えない壁にぶつかるAIデータセンター
近年、AIが話題にのぼる際、会話は常にGPUの数や計算能力から始まる。しかし、そこには見落とされがちな前提がある。いかに計算が速くても、データが移動できなければ、すべては無に帰すということだ。GPUはラックの中でアイドリング状態になり、電力は消費され続け、設備投資が有効な計算出力に変換されることはない。
今日の主流なデータセンター・インターコネクトは、おおよそ以下のような役割分担になっている。
- ラック内や数メートル以内の短距離リンクでは、安価で導入が容易なDAC/AEC銅ケーブルが主流である。
- ラックや列を跨ぐ場合、特にアグリゲーション層やバックボーン層では、実質的にファイバーと光モジュールによる「オール・オプティカル」の世界となる。2025年頃の大規模な新設データセンターでは、バックボーンや長距離インターコネクトの80%以上がすでにファイバー・ソリューションに直接移行している。
コンピューティング密度が最も高い極めて狭い領域、つまりラック内やボード間では、今日のほとんどのAIクラスターが依然として銅線を利用している。まさにそのために、帯域幅が400Gや800Gから1.6Tへと向上すると、物理的限界に達したこの短い区間の銅線が真っ先に破綻することになる。
1. 周波数が高くなるほど、銅線への負荷が増す。表皮効果は避けられない。
100G/200Gクラスの高周波では、電流はもはや銅の断面全体を一様に流れることはない。導体の表面近くのリング状の部分に押し込められる。これが古典的な表皮効果である。太い銅線にコストを払っても、実際に高周波信号を運ぶのは表面の薄い層だけであり、実効断面積は縮小し続ける。
1レーンあたり112Gや224GのPAM4で動作させ続けるためには、設計者はケーブルを太くし、より高価な誘電体を使用し、基板上の配線や曲げスペースをより多く確保するしかない。その結果、ケーブルはより硬く、重く、かさばるようになり、ラックのスペース、エアフロー、冷却への負荷が連動して増大する。
2. 距離が伸びると、高速銅線は耐えられなくなる。
データレートを2倍にするたびに、従来の銅線リンクの到達距離は激減する。400Gの段階では、1レーン100Gのパッシブ銅ケーブル(DAC)は通常、3〜5メートル程度なら安定して動作させることができた。信号整合性とビット誤り率(BER)は、増幅やイコライゼーションのためのチップを両端に追加せずとも、工学的に設計可能な範囲内だった。しかし、800Gおよび1レーン112Gになると、多くのベンダーはパッシブDACの長さを2メートル未満に抑えるべきだと推奨している。それ以上の距離ではアイパターンが極端に劣化し、BERを許容範囲内に維持することが困難になるからだ。
さらに1.6Tおよび1レーン224Gへと突き進むと、チップを追加せずにパッシブ銅ケーブルのみに頼る場合、実用上はわずか1メートル程度の有効長しか設計できなくなる。長距離化を強行するには、両端に増幅、イコライゼーション、リタイミングを行う小型チップを追加してアクティブ電気ケーブル(AEC)にする必要がある。これにより距離は3〜7メートル程度まで伸びるが、ケーブル1本あたりのコスト、消費電力、システム複雑性は明らかに増大する。
真の問題は、AIクラスターが最も高い帯域幅と低遅延を求めるリンクが、往々にして数十メートルに及ぶこともあるラック間や列間であるという点だ。言い換えれば、ワークロードが理想とするネットワーク規模は、1.6Tにおける銅線の物理的な「快適ゾーン」をすでに遥かに超えて成長しているのだ。だからこそ、AIデータセンターは文字通り銅線の物理的な天井に突き当たっていると言える。
3. 消費電力が桁違いに変わる可能性がある。
従来のアプローチは次のように要約できる。「長い銅線が短い光ファイバーを引きずる」。GPUやスイッチASICからの信号は、まず筐体内の高速銅線トレースを長く走りフロントパネルへと向かい、そこでプラグ着脱式の光モジュールに渡される。このモジュールには高負荷なDSP、FEC、イコライゼーション回路が搭載されており、電気・光変換を行う。これが今日のほとんどの800G/1.6T光モジュールの典型的な形態であり、1.6Tモジュールの消費電力は通常20〜25Wの範囲に達する。実質的に、電力を消費して強引に銅線チャネルの損失を補っている状態だ。
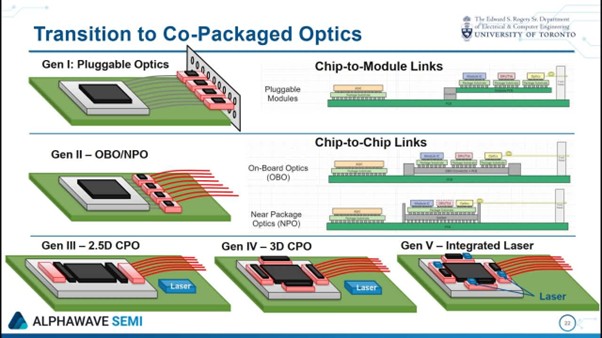
出所:Microelectronics
CPO(共同パッケージ光技術)はこの経路を逆転させ、次のように要約できる。「光が演算のすぐ隣を走る」。CPOは光エンジンをスイッチASICやXPUのすぐ隣に配置する。そのため、高速電気信号はパッケージや基板上を数ミリから数センチ移動するだけで光に変換され、その後の経路はすべて光ファイバーとなる。消費電力が大きく長い高速銅線のセグメントが、光に置き換わるのだ。Nubisなどのベンダーのデータによれば、CPO/NPOアーキテクチャ下では、1.6T光エンジン全体を約5〜8Wの範囲に収めることが現実的であり、ポートあたり数十ワット単位の節電が可能になる。単一のボードレベルでは劇的な差に聞こえないかもしれないが、数千の広帯域ポートを備えたAI「工場」では、数十から数百キロワット単位の電力差が生じることになる。
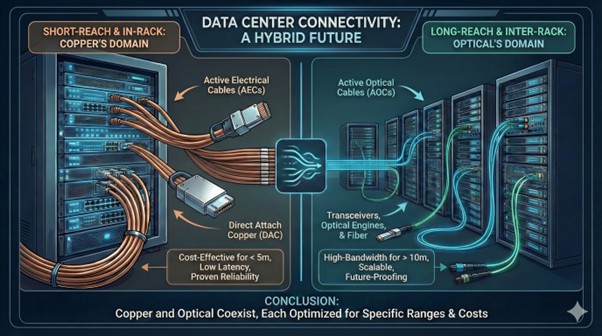
出所:Astera Labs
したがって、これら3つの次元において、光ファイバーは銅線をほぼ完全に圧倒している。帯域密度については、1本のファイバーに多波長を重畳することで、ケーブルを太くすることなく多車線道路のように拡張できる。到達距離については、シングルモードファイバーであれば数十から数百メートルが通常の動作範囲であり、同様の周波数における損失や符号間干渉(ISI)は銅線よりも遥かに小さい。消費電力についても、ガラス内を伝搬する光信号は表皮効果や大きな静電容量の充放電の影響を受けないため、本質的にエネルギー効率が高い。
この時点において、もはや「銅か光か」という純粋な技術論争ではなく、どの速度で、どのインターコネクト層において業界が完全に光へと移行するかという問題になっている。800Gから1.6Tへと、この移行スケジュールはAIデータセンターによって一歩ずつ前倒しされている。
光インターコネクトの3つの進化経路
光インターコネクトは単一のソリューションではなく、段階的に展開される重層的なテクノロジースタックである。大まかには、次の3つの経路を辿る。まずプラグ着脱式光モジュールを導入し、次に光技術をチップに近づけ、最終的にはスイッチング・アーキテクチャそのものを変える。これら3つの経路を理解すれば、今後数年間で誰が恩恵を受け、誰が圧迫されるのかを本質的に把握したことになる。
プラグ着脱式光モジュール ―― 今日の主力
これは、今日のデータセンターにおいて最も成熟した光インターコネクトの形態である。モジュールはスイッチのフロントパネルに配置され、ホットスワップや保守が容易だ。400Gから800G、および1.6Tへと、プラグ着脱式ソリューションの導入は急速に進んでいる。LumentumのEMLレーザーチップは、これらのモジュールにおける主要な光源である。同社の100G EMLの出荷量は過去最高を記録しており、200G EMLも急速に拡大している。
CPO/NPO ―― 未来の統合ソリューション
CPOは光エンジンをスイッチパッケージに直接統合することで、電気・光変換の経路を根本的に短縮し、電力消費と遅延を大幅に削減する。GTC 2025において、NvidiaはシリコンフォトニクスをベースとしたSpectrum-XおよびQuantum-Xスイッチを初めて披露し、ポートあたり1.6Tbpsの帯域幅を実現した。NPO(Near-Packaged Optics)はCPOへの移行形態であり、光エンジンを数センチ離れたPCB上に配置することで、電力効率と保守性のバランスを取っている。
Bernsteinによれば、スケールアウト・シナリオにおける大規模なCPO/NPOの出荷は2026年後半から2027年頃に始まると予想されているが、信頼性がより重視されるスケールアップ・シナリオでは、2028年後半より前に量産される可能性は低い。
OCS ―― スイッチング・ファブリックの再定義
最初の2つの経路は、既存のEthernetやInfiniBandのロジックを維持しつつ、銅線を光に置き換え、光をより適切な場所へ移動させることに重点を置いている。それに対し、OCS(光サーキットスイッチ)はより急進的だ。中間の電子スイッチング層を完全にバイパスする。OCSはMEMSマイクロミラーアレイを使用して光をファイバー間で直接誘導する、その間、電気信号への変換は一切行われない。これにより、従来のスイッチにおける複数のO-E-O変換を完全に回避する。Googleは、自社のデータセンターネットワークにこの技術を大規模に導入した先駆者である。LumentumのR300はこの経路を代表する製品であり、ハイパースケール・クラウドプロバイダー向けの光主配線盤として、単一の筐体で300×300ポートを提供している。
技術パス | 消費電力 (1.6T) | 伝送距離 | 商用化フェーズ | 代表的なベンダー |
プラガブル光モジュール | 20~30 W | 数十~数百メートル | 量産 | Innolight、LITE、Coherent |
NPO | 約9 W | 数十~数百メートル | 2026年に試作開始 | Nvidia、Broadcom |
CPO | 5~8 W | 数十~数百メートル | 2026~2027年に量産開始 | Nvidia + TSMC + LITE |
OCS | 極めて低い | 数十~数百メートル | 大手クラウドが導入 | Google、LITE |
Lumentum:なぜ同社が最大の恩恵を受けるのか
スピンオフから垂直統合へ:10年にわたる布石
Lumentum(LITE)は、老舗の光通信メーカーJDSUからスピンオフし、2015年に独立上場を果たした。当初は中堅の光コンポーネント企業としてスタートしたが、その後の10年間で3つの買収を行い、その立ち位置を徐々に変えてきた。
- 2018年のOclaro買収(約18億ドル):高速データ通信用レーザーの中核材料であるInP(インジウムリン)レーザーの設計および製造能力を全面的に獲得した。
- 2022年のNeoPhotonics買収:長距離コヒーレント光通信の製品ポートフォリオを強化した。
- 2023年のCloud Light買収(約7億5000万ドル):高速クラウド用光モジュール市場に参入し、アジアの主要モジュールメーカーと直接競合するようになった。
独立から10年が経過する2026年までに、Lumentumはレーザーチップやコンポーネントのサプライヤーから、レーザーチップ、光モジュール、光スイッチングシステムまでを網羅する垂直統合型プラットフォームへと進化した。
フォトニクス分野のIDM:その重要性とは
半導体業界において、IDM(垂直統合型デバイスメーカー)は設計から製造までを一貫して管理することを意味する。フォトニクス分野におけるLumentumの役割は、このモデルを密接に反映している。
自社保有のInPファブ:日本の相模原や高尾、英国のカズウェルなどにInP光ウェハーおよびレーザーの生産ラインを保有している。InPの供給が逼迫する世界において、こうした内製能力は極めて希少である。
バリューチェーン全体の網羅:InPウェハー上へのレーザーチップ形成から、タイ・バンコク近郊のナワナコン工業団地での光モジュール組み立て、さらにはOCSシステムの提供に至るまで、バリューチェーンの上流・中流・下流すべてに拠点を構えている。
継続的な生産能力の拡大:2024年末に開始された40%以上のInP生産能力拡大計画は、すでに半分以上が完了しており、同社はさらなる増産に向けて新工場の建設やM&Aを検討している。
供給制約が発生するサイクルにおいて、このような垂直統合は価値を高める。他社がチップの納品を待つ間、Lumentumは自社で製造することができるからだ。
4つの製品ライン、4つの成長エンジン
エンジン1:EMLレーザーチップ
EML(電界吸収型変調レーザー)は、800Gおよび1.6Tモジュールの基幹光源である。Lumentumの100G EMLは出荷記録を更新し続けており、200G EMLは2025年12月期においてデータ通信用レーザー収益の約10%を占めている。経営陣は、そのシェアが2026年末までに25%に達すると予想している。200Gデバイスは100Gよりも単価が高く、平均販売価格(ASP)と粗利益率の両方を押し上げている。また、同社は1レーンあたり400Gの3.2Tモジュールを見据え、448 Gbpsの次世代EML技術も披露している。
エンジン2:CWレーザーとELSモジュール ―― CPOの心臓部
CPO(共同パッケージ光通信)アーキテクチャでは、変調がシリコンフォトニクスPIC上で行われるため、モジュール自体にレーザーを内蔵する必要がなく、代わりに外部の連続波(CW)レーザーを光源として使用する。これらのCWレーザーは、高温環境下で数百ミリワットの安定した光出力を維持する必要があり、極めて高度なInPデバイスおよびパッケージング技術が求められる。これこそが、LumentumがNvidiaなどの主要顧客に選ばれている理由である。
直近の決算説明会において、経営陣は超高出力レーザーに関する数億ドル規模の複数の受注を明らかにし、2027年上半期から納入を開始する計画を示した。さらに重要なのは、同社がベアチップ(レーザーチップ単体)の供給から、モジュール化したELS(外部光源)の提供へと領域を拡大している点である。ELSの単価はチップ単体の約2倍から2.5倍に相当し、獲得可能な市場(TAM)を大幅に拡大させている。
エンジン3:OCS(光回線スイッチング)システム
3D-MEMSマイクロミラーをベースとしたLumentumのR300 OCSは、大手ハイパースケール・クラウド顧客3社から4億ドル以上の受注残を抱えている。2026年度第2四半期決算において、経営陣はOCSの出荷ペースが社内予想を上回り、四半期売上高が予定より早く1,000万ドルの大台を突破したと言及した。受注残の大部分は2026年後半に出荷される見通しだ。
みずほ証券の予測によれば、2029年までにデータセンター向けOCSのTAM(最大獲得可能市場)は約19億ドル(年平均成長率(CAGR)は約44%)に達し、Lumentumは30〜40%の市場シェアを獲得する可能性がある。
エンジン4:クラウド光モジュール
Cloud Lightの買収を通じて取得した高速トランシーバー事業が急速に拡大している。2026年度第2四半期のシステム売上高は2億2,180万ドル(前年同期比60%増)に達し、クラウド光モジュールが最大の成長ドライバーとなった。経営陣は、1.6Tモジュールの利益率が800G製品を大幅に上回ることを強調しており、1.6Tの増産に伴い、同セグメントの収益性は向上し続けるとみられる。
財務上の転換点:数字が語る実態
具体的な数字を見れば、Lumentumの転換点はすでに明らかだ。2026年度第2四半期の売上高は6億6,550万ドルと、前年同期比65.5%増、前四半期比で約25%増となり、上場以来最高の四半期売上高を記録した。
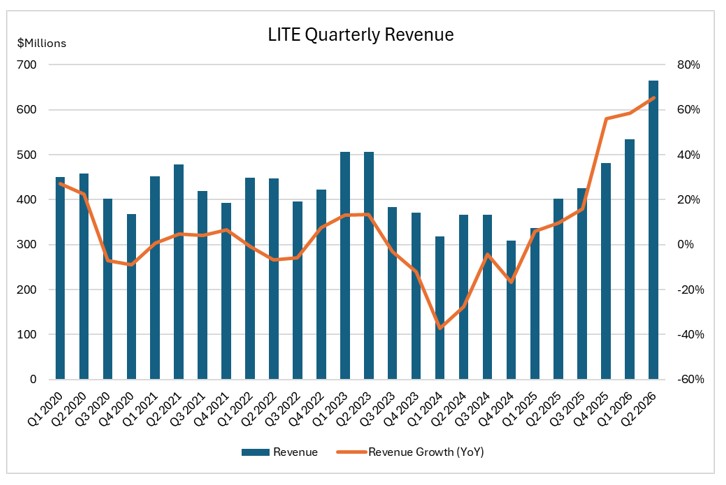
出所:LITE四半期報告書、TradingKey
粗利益率は前年同期の約25%から36%に上昇し、営業利益率は約マイナス12.8%からプラス9.7%へと改善。GAAP(一般会計原則)ベースのEPS(1株当たり利益)は、2025年度第2四半期のマイナス0.88ドルから2026年度第2四半期にはプラス0.89ドルへと黒字転換した。これらの一連の変化は、売上高が急成長する一方で収益性が希薄化しておらず、むしろ赤字脱却から持続的な収益化へと進展していることを示している。
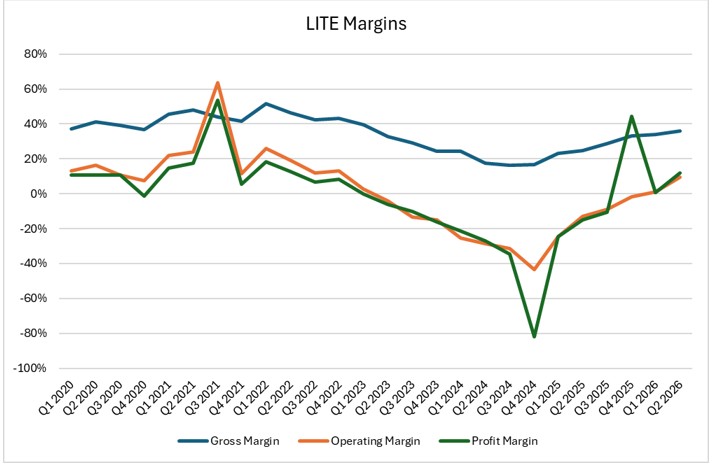
出所:LITE四半期報告書、TradingKey
2025年度後半から2026年度にかけて、成長の傾斜は明らかに急になっている。売上高は加速し、利益率は段階的に上昇しており、これは単なる一時的な反発ではなく、数量増と価格改善が相まった典型的な転換点といえる。
さらに重要なのは、この改善が単一の四半期に限った話ではないことだ。2026年度第3四半期について、経営陣は売上高見通しを前年同期比でほぼ倍増となる7億8,000万〜8億3,000万ドルとしている。
リスクと議論の焦点
バリュエーションは割安ではない
2027年度のコンセンサス予想EPS(約11ドル)に基づくと、現在の約670ドルという株価は、予想PER(株価収益率)で約60倍に相当する。より楽観的な機関投資家は、2027年度のEPSを17〜24ドルと予測しており、その場合のバリュエーションは約30倍まで低下する。いずれにせよ、現在の価格にはすでに強い成長期待が織り込まれている。最大の焦点は、Lumentumが依然としてサイクル性の強い光部品メーカーにとどまっているのか、それとも構造的なAI光相互接続プラットフォームとしての軌道に真に乗ったのかという点だ。
技術経路の不確実性
CPO(共同パッケージ化光学)の試験運用と、真の大規模展開の間には不確実性が存在する。スケールアップ・シナリオにおけるCPOは、実際の環境での長期的な信頼性検証が依然として必要だ。また、Co-packaged Copper(CPC:共同パッケージ化銅)などの代替オプションも、スケールアップのユースケースにおける短距離相互接続の需要を巡って競合している。
顧客集中度
OCSの注文は現在、主に3社のハイパースケール顧客に集中している。OCSがこれらの主要クラウド事業者以外へとより広い市場に拡大できなければ、成長の天井は期待を下回る可能性がある。
競争の激化
レーザー分野では、CoherentがInP(インジウムリン)ラインを4インチから6インチウェハーにアップグレードしており、ウェハーあたりの出力が4倍になる可能性がある。光モジュール分野では、中国ベンダー(Innolightなど)がレーザーチップの上流工程に進出している。Lumentumが現在の技術的・生産能力的優位性を維持できるかどうかは、研究開発(R&D)のペースを維持できるかにかかっている。
結論
Lumentumの成長ロジックは、明確な因果関係の連鎖に集約される。AIクラスターの拡大継続 → GPU間の帯域幅需要の指数関数的増加 → 銅配線が物理的限界に到達 → 光相互接続が唯一の解決策となる → レーザーは光チェーンの起点に位置する → ハイエンドのAIグレード・レーザーを製造できる企業は極めて少ない → IDM(垂直統合型デバイスメーカー)形式の統合と10年にわたるM&Aを経て、Lumentumはこの重要拠点において最も広範なプレゼンスを構築した。
同社は3つの成長曲線を同時に描いている。800G/1.6T着脱式モジュールの増産、CPO/NPOのゼロからイチへの商業化、そして複数のハイパースケール・クラウドにおけるOCSの普及だ。2026年から2027年にかけてこれら3つの曲線が同時に上昇することは、光通信の歴史においても極めて稀である。
もちろん、670ドルという株価にはすでに非常に高い期待が織り込まれている。重要な試金石はすぐ先に控えている。来週のGTC(GPUテクノロジー・カンファレンス)とOFC(光ファイバー通信会議)は、CPOの増産スケジュール、OCSの顧客多様化、そしてエヌビディア(Nvidia)の次世代アーキテクチャにおける光相互接続の役割について、重要な示唆を与えることになるだろう。
免責事項:本記事は業界分析および情報共有のみを目的としており、いかなる投資助言や推奨を構成するものではありません。投資にはリスクが伴います。投資決定は、ご自身の独立した判断に基づき、専門家のアドバイスを受けた上で行ってください。